链表是线性表的一种实现方式,它的基本想法是:
将表中的元素分别存放在各个独立的存储区内,存储区又称为结点;
在表中,可以通过任意结点找到与之相关的下一个结点;
在前一个结点上,通过链接的方式记录与下一个结点的关联。
当找到组成表结构的第一个结点时,就能按照顺序找到属于这个表的其它结点。
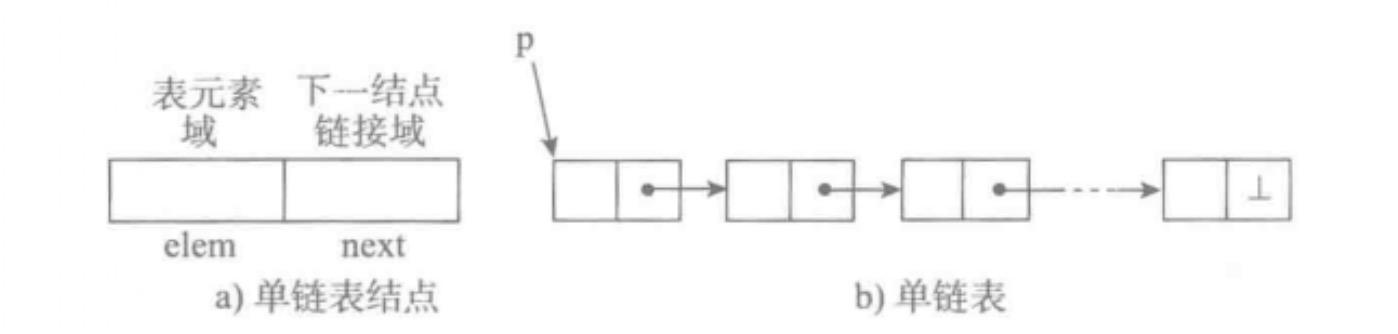
单链表 如上图(a)所示,单链表的结点是一个二元组,elem保存元素的数据,next表示下一个结点的标识。
为了掌握一个单链表,需要用一个变量来保存这个表的首结点的引用(或标识),该变量可以称之为表头变量或 表头指针
基本链表操作
创建空链表
删除链表
判断链表是否为空
加入元素
删除元素
遍历链表
查找元素
代码实现,里面实现几个典型方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 class Node : """结点""" def __init__ (self, elem) : self.elem = elem self.next = None class SingleLinkList : """单链表""" def __init__ (self) : self._head = None def is_empty (self) : """链表是否为空""" return self._head == None def length (self) : """链表长度""" cur = self._head count = 0 while cur != None : count += 1 cur = cur.next return count def travel (self) : """遍历整个链表""" cur = self._head while cur != None : print(cur.elem, end=" " ) cur = cur.next print("" ) def add (self, item) : """链表头部添加元素,头插法""" node = Node(item) node.next = self._head self._head = node def append (self, item) : """链表尾部添加元素, 尾插法""" node = Node(item) if self.is_empty(): self._head = node else : cur = self._head while cur.next != None : cur = cur.next cur.next = node def insert (self, pos, item) : """指定位置添加元素 :param pos 从0开始 """ if pos <= 0 : self.add(item) elif pos > (self.length()-1 ): self.append(item) else : pre = self._head count = 0 while count < (pos-1 ): count += 1 pre = pre.next node = Node(item) node.next = pre.next pre.next = node def remove (self, item) : """删除结点""" cur = self._head pre = None while cur != None : if cur.elem == item: if cur == self._head: self._head = cur.next else : pre.next = cur.next break else : pre = cur cur = cur.next def search (self, item) : """查找结点是否存在""" cur = self._head while cur != None : if cur.elem == item: return True else : cur = cur.next return False
通过上面的代码,可以说明一下单链表的操作复杂度:
创建空链表:O(1)
判断链表是否为空:O(1)
链表长度:O(n)
加入元素:
首端加入:O(1)
尾端加入:O(n)
中间加入:O(n)
删除元素:
首端删除:O(1)
尾端删除:O(n)
中间删除:O(n)
遍历,查找:O(n)
上面的单链表实现有个缺点,在尾端操作元素的效率低,只能从表头开始遍历到尾部。
循环单链表 单链表的一种变形是循环单链表,它的最后一个结点的next不指向None,而是指向首结点的位置,如上图所示。
代码实现,部分和单链表类似
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 class SingleCycleLinkList : """单向循环链表""" def __init__ (self) : self._head = None def add (self, item) : """链表头部添加元素,头插法""" node = Node(item) if self.is_empty(): self._head = node node.next = node else : cur = self._head while cur.next != self._head: cur = cur.next node.next = self._head self._head = node cur.next = self._head def append (self, item) : """链表尾部添加元素, 尾插法""" node = Node(item) if self.is_empty(): self._head = node node.next = node else : cur = self._head while cur.next != self._head: cur = cur.next node.next = self._head cur.next = node def insert (self, pos, item) : """指定位置添加元素 :param pos 从0开始 """ if pos <= 0 : self.add(item) elif pos > (self.length()-1 ): self.append(item) else : pre = self._head count = 0 while count < (pos-1 ): count += 1 pre = pre.next node = Node(item) node.next = pre.next pre.next = node def remove (self, item) : """删除结点""" if self.is_empty(): return cur = self._head pre = None while cur.next != self._head: if cur.elem == item: if cur == self._head: rear = self._head while rear.next != self._head: rear = rear.next self._head = cur.next rear.next = self._head else : pre.next = cur.next return else : pre = cur cur = cur.next if cur.elem == item: if cur == self._head: self._head = None else : pre.next = self._head
其它的方法和单链表一样。
同样的,可以添加一个尾部结点的引用,使得运算量下降。
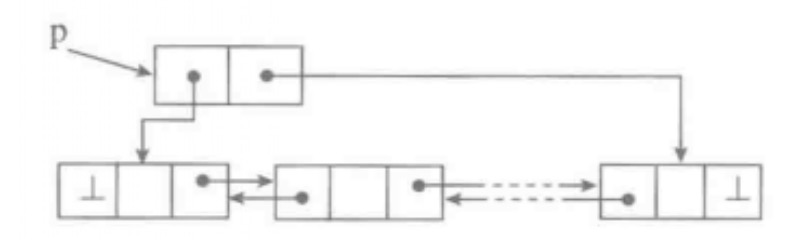
双向链表 单链表只有一个方向的链接,从一个方向进行链表的遍历。为了是从两端的插入和删除操作都能高效完成,可以加入另一个方向的链接。如上图所示,就形成了双向链表,或 双链表
双向链表的结点除了next引用,还需要一个prev引用:
1 2 3 4 5 6 class Node (object) : """结点""" def __init__ (self, item) : self.elem = item self.next = None self.prev = None
双向链表的一些操作要做一些修改:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 class DoubleLinkList (object) : """双链表""" def __init__ (self) : self._head = None self._rear = None def add (self, item) : """链表头部添加元素,头插法""" node = Node(item) if self.is_empty(): self._rear = node node.next = self._head self._head = node node.next.prev = node def append (self, item) : """链表尾部添加元素, 尾插法""" node = Node(item) if self.is_empty(): self._head = node else : cur = self._head while cur.next != None : cur = cur.next cur.next = node node.prev = cur self._rear = node def insert (self, pos, item) : """指定位置添加元素 :param pos 从0开始 """ if pos <= 0 : self.add(item) elif pos > (self.length()-1 ): self.append(item) else : cur = self._head count = 0 while count < pos: count += 1 cur = cur.next node = Node(item) node.next = cur node.prev = cur.prev cur.prev.next = node cur.prev = node def remove (self, item) : """删除节点""" cur = self._head while cur != None : if cur.elem == item: if cur == self._head: self._head = cur.next if cur.next: cur.next.prev = None else : self._rear = None else : cur.prev.next = cur.next if cur.next: cur.next.prev = cur.prev else : self._rear = cur.prev break else : cur = cur.next
总结 链接表的优点:
由于表结构是由链接起来的结点形成,表结构很容易修改;
整个表由一些小的存储块构成,比较容易安排和管理,不需要连续的内存块。
缺点:
链表元素的定位需要线性的时间,比列表效率底;
链表的存储代价会比列表高。